Без мониторинга компания обычно узнаёт о сбое последней — уже после жалоб сотрудников, клиентов или остановки важного сервиса.
Проблемы на серверах и в сети замечают слишком поздно.
Оповещения приходят только от людей, а не от инфраструктуры.
Нет нормальной истории, чтобы понять, что происходило до инцидента.
Когда появляется мониторинг, его часто настраивают слишком шумно и им перестают пользоваться.
Что определить заранее
Чтобы мониторинг был полезным, важно заранее решить несколько вещей.
Какие серверы, сервисы, коммутаторы и узлы действительно критичны.
Какие метрики и события важны для бизнеса и поддержки.
Кому и как должны приходить оповещения.
Где проходит граница между полезным сигналом и лишним шумом.
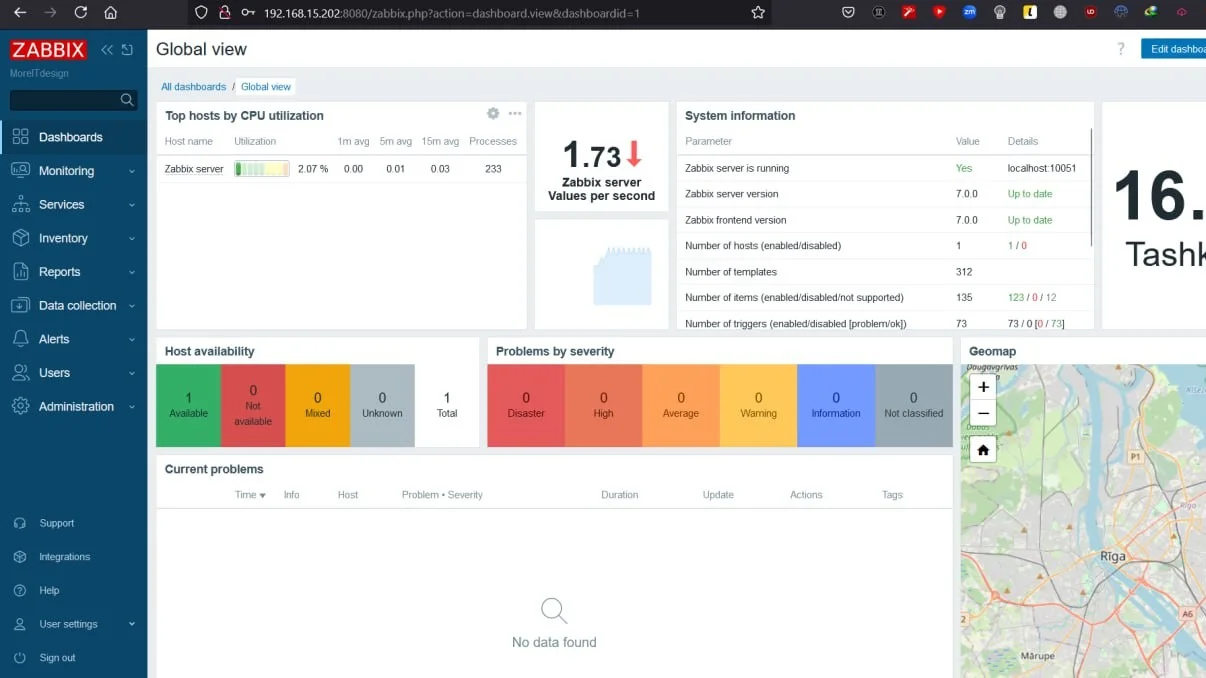
Практическое решение
Zabbix-мониторинг должен давать внятную картину состояния инфраструктуры и адекватные оповещения.
Подключаем критичные узлы: серверы, сеть, хранилища и ключевые сервисы.
Настраиваем шаблоны, триггеры и оповещения без лишнего информационного шума.
Смотрим тренды и историю, чтобы видеть деградацию до аварии.
Оставляем мониторинг, которым реально пользуются, а не просто держат включённым.
Полезный совет
Лучший мониторинг — тот, где каждое оповещение действительно заслуживает внимания, а не теряется среди десятков второстепенных событий.
Очень полезно смотреть не только аварии, но и тренды: рост загрузки, диска, памяти и задержек по времени.
Быстрый контакт
Коротко опишите ситуацию: что сейчас не работает, на какой процесс это влияет и какой результат для вас важнее всего. Мы посмотрим на задачу по-человечески и без лишних слов подскажем самый быстрый и здравый путь решения.